
Performance du Service Desk : factualiser l’origine de l’incident IT
Aujourd’hui, la performance d’une entreprise dépend en grande partie de son Système d’Information. C’est la raison pour laquelle le Service Desk est stratégique. Il doit veiller sur le bon fonctionnement du réseau et des applicatifs, poser de bons diagnostics mais aussi… anticiper ! Pour mener à bien cette mission, une expertise et des outils spécifiques sont nécessaires. Voici notre analyse en 2 temps.

Temps 1 / l’analyse réseau : Quality Of Service (QoS) également appelée Network Performance Management (NPM)
Dans un premier temps, le Service Desk mesure la performance entre le site distant (site utilisateur) et le site central (Data Center): l’incident est-il constaté sur le site utilisateur ou chez l’hébergeur (Data Center) ? Si l’application est, par exemple, hébergée à New-York et que l’utilisateur se trouve à Dublin, à quel niveau se situe l’encombrement ? Quel est le délai réseau ? Est-ce un temps acceptable ? Y-a-t-il des perturbations (pertes de paquets) ? L’anomalie est-elle détectée entre le DC et le site utilisateur ou l’inverse ?
Le Service Desk va ensuite mesurer à la fois la charge du lien internet (MPLS) du site distant et celle du Data Center (bande passante (trafic entrant/sortant, erreurs d’interface), analyse des classes de services, etc…). Il va aussi relever les métriques liées à la charge du serveur (CPU/RAM, services = process JVM) qui héberge l’applicatif (Data Center).
Y-a-t-il saturation ou un éventuel problème de configuration ? Ces analyses permettent de dimensionner les ressources (capacity planning) de façon à éviter le surdimensionnement (coûts inutiles) ou le sous-dimensionnement (baisse de performance). On peut compléter cette analyse grâce au protocole Netflow qui, à travers le Top Report, permet d’identifier plus précisément ce qui sature le trafic.
Si les tests révèlent que le problème ne vient pas de l’infrastructure réseau, il ne peut venir que de la couche applicative qu’il s’agit maintenant de tester à son tour.
Temps 2 / L’étude applicative : Quality Of Experience (QoE) ou Application Performance Management (APM)
Evaluer le ressenti utilisateur requiert la mise en place de scripts applicatifs qui simulent l’expérience utilisateurs. On peut la mesurer grâce à l’exécution, à intervalles réguliers, de scripts (scénarii) d’utilisation des applications critiques de l’entreprise. Ceux-ci sont joués depuis différents sites pour identifier le lieu névralgique :
- depuis le site distant (site utilisateurs)
- depuis le Cloud
- au data center.
Ces scripts métiers permettent d’identifier quelle page ou quel élément de l’applicatif est responsable d’un éventuel ralentissement.
Ces deux types d’analyses de la performance sont complémentaires (QoS + QoE) et fondent une vision consolidée.
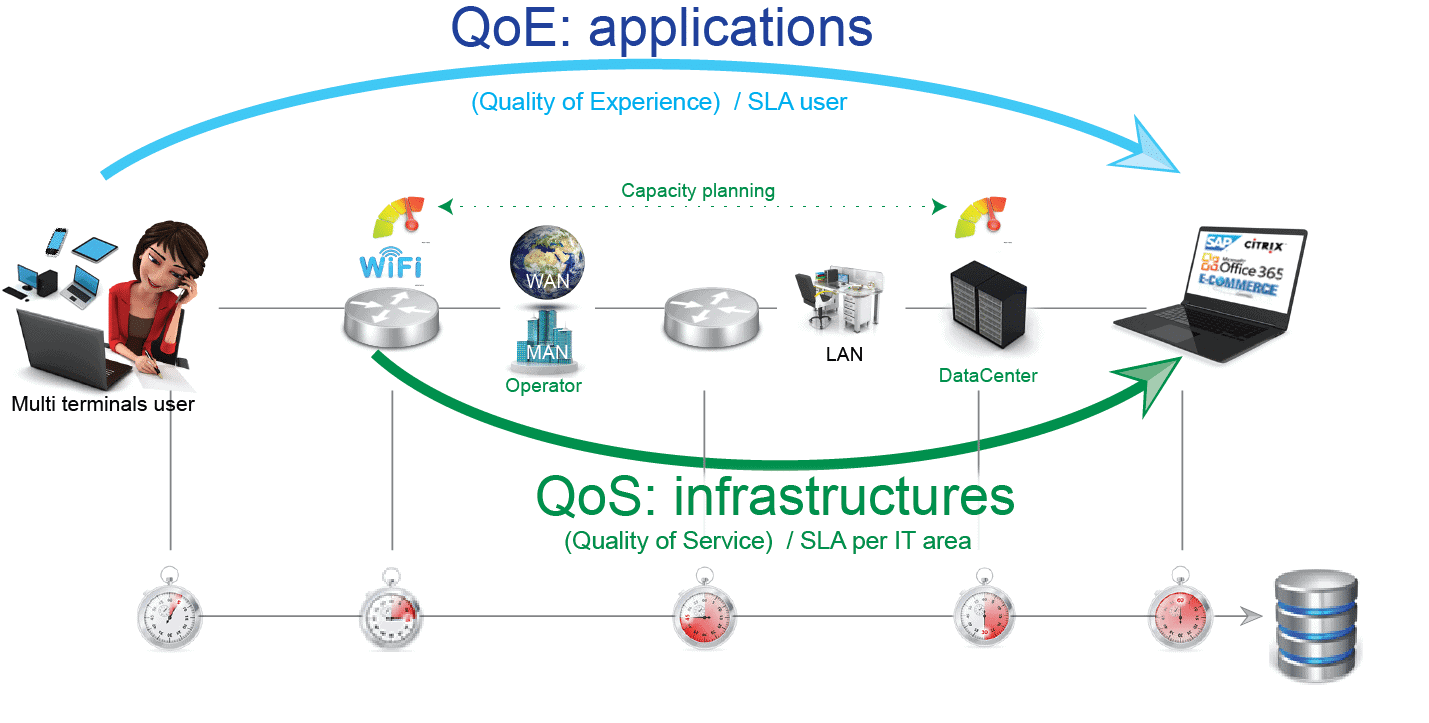
Une vision consolidée pour votre Service Desk
Pour piloter la performance IT, qu’elle soit applicative ou réseau, il est nécessaire d’avoir une vision continue et ciblée du Système d’Information, comme recommandé par les bonnes pratiques ITIL.
Détenir la bonne information au bon moment permet :
- de prendre les meilleures décisions
- de centraliser les informations issues d’un grand nombre de sources
- d’avoir une maîtrise globale des trafics aux points clés de l’architecture (Data Center, accès Internet, etc.).
En évaluant le QoS et le QoE et en croisant toutes ces données, on peut identifier très finement les origines d’un incident, d’un ralentissement, d’un dysfonctionnement et y remédier dans les meilleurs délais.
Ainsi, Maltem Insight Performance délivre une vision précise du ressenti utilisateur, de la performance des applications, des réseaux et des infrastructures grâce à une stratégie de mesures élaborée en conformité avec les réalités de votre métier.